Rens Dimmendaal personal site
How I Use AI to Learn
Some people think because of AI we don't need to learn new things anymore. The AI can do everything for you right?
I dont think so. And not just because AI isnt perfect. The more important part is that I love learning new things. And I want AI to help me learn more not less.
So, in this talk I show how I use AI to learn new things. And what are properties of AI tools that I found that make them great for learning.
I gave this talk at the MLOps.community Amsterdam and I got some positive reactions. So I figured I'd record another take so I could put it on youtube and share it with others.
learning mode lite
Solveit has a great learning mode. It really helps me stay actively engaged without falling into passive consumer mode when working with AI.
It's important to note that it's not a prompt but a larger system. And I really miss it when im using other tools.
Below is a simpler, lighter version...though it's not quite as good, of course.
TIL: grep bracket [t]rick
When you use grep to search for a running process, you often see the grep command itself in the results:
$ ps aux | grep 'python'
user 1234 python myapp.py
user 5678 grep python # <-- unwanted!
To avoid it you wrap the first letter in brackets:
$ ps aux | grep '[p]ython'
user 1234 python myapp.py # only the real match!
This works because [p]ython matches python but it doesn't match the string [p]ython. So grep filters itself out automatically.
The Solveit approach turns frustrating AI conversations into learning experiences
"Here's a complete web app that does what you asked for!"
ChatGPT cheerfully responded, while presenting me with an intimidating wall of code. I had simply asked for help creating a small weather dashboard. At a first glance, the code looked fine. Imports, API calls, state management, and even error handling. But when I tried to run it, nothing worked. So of course, I paste the error message and ask for a fix.
"Oh, I see the issue, here's the corrected version..."
...And two new bugs appeared. Three responses later, the code was worse than when I started. And more importantly, I had no idea what was going on.
To me, most AI tools feel like using a self-driving car that all of a sudden decides to drive off a cliff.
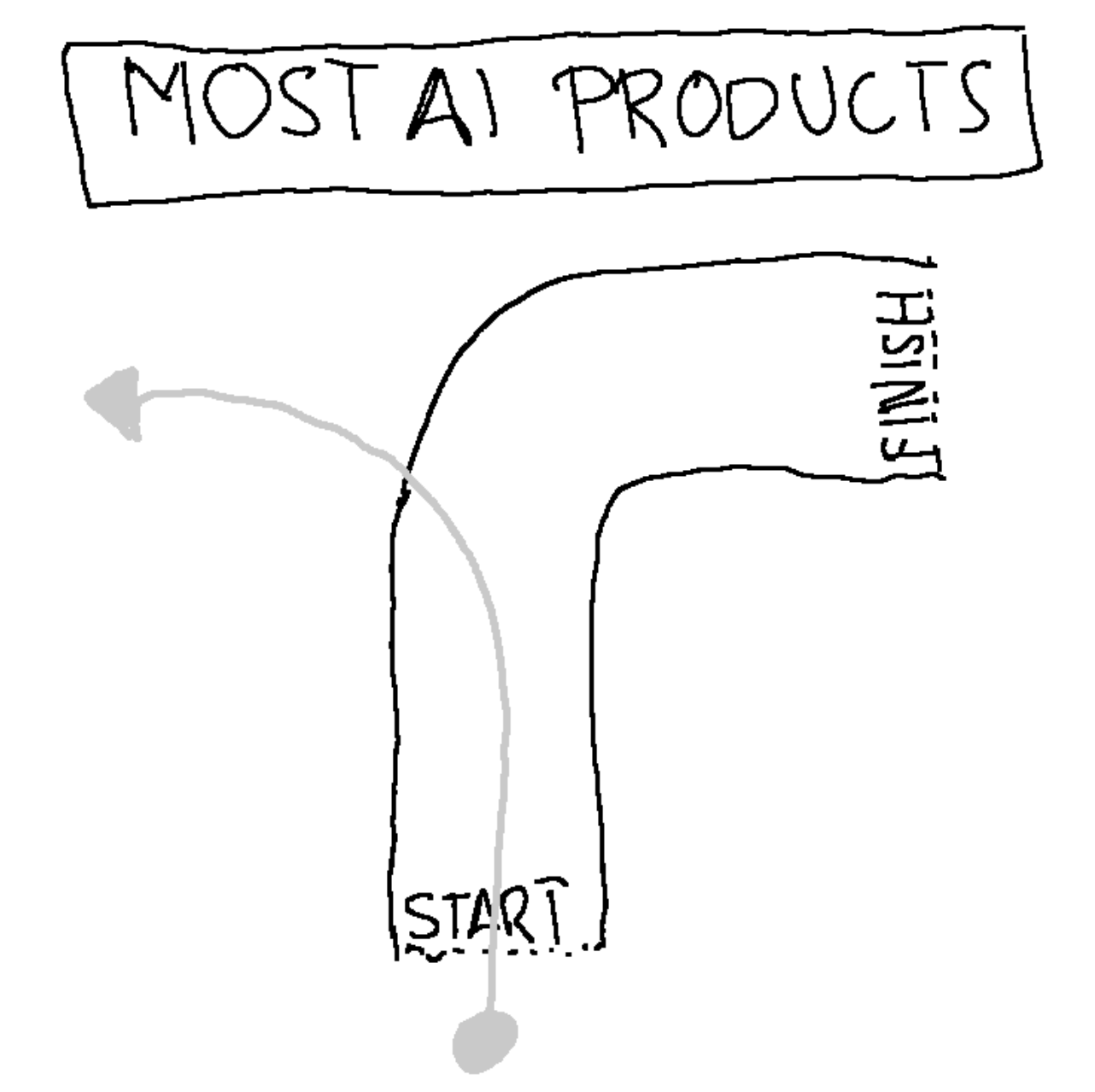
This pattern, the "doom loop of deteriorating AI responses", is something I've encountered repeatedly. It's particularly frustrating because these AI tools seem so promising at first!
Enter Solveit, a tool designed specifically to transform these frustrations into learning experiences. In AnswerAI's "Solve It With Code" course, led by Jeremy Howard and Johno Whitaker, I learned not just how to use this tool, but the fundamental principles behind effective AI interaction that apply to working with any AI assistant.
In this post, I'll share the three key properties of LLMs that cause the doom loop, and the three techniques that transform it into a learning loop. It's what they've come to call "the Solveit approach."
The TL;DR of this post can be summarized with this table:
| LLM Property | Consequence | Solve It Solution |
|---|---|---|
| RLHF | Over eager to give long complete responses | Work in small steps, ask clarifying questions, check intermediate outputs |
| Autoregression | Deterioration over time | Edit LLM responses, pre-fill responses, use examples |
| Flawed and outdated training data | Hallucinations and outdated information | Include relevant context |
Or if you're the visual type, with this beautiful illustration:
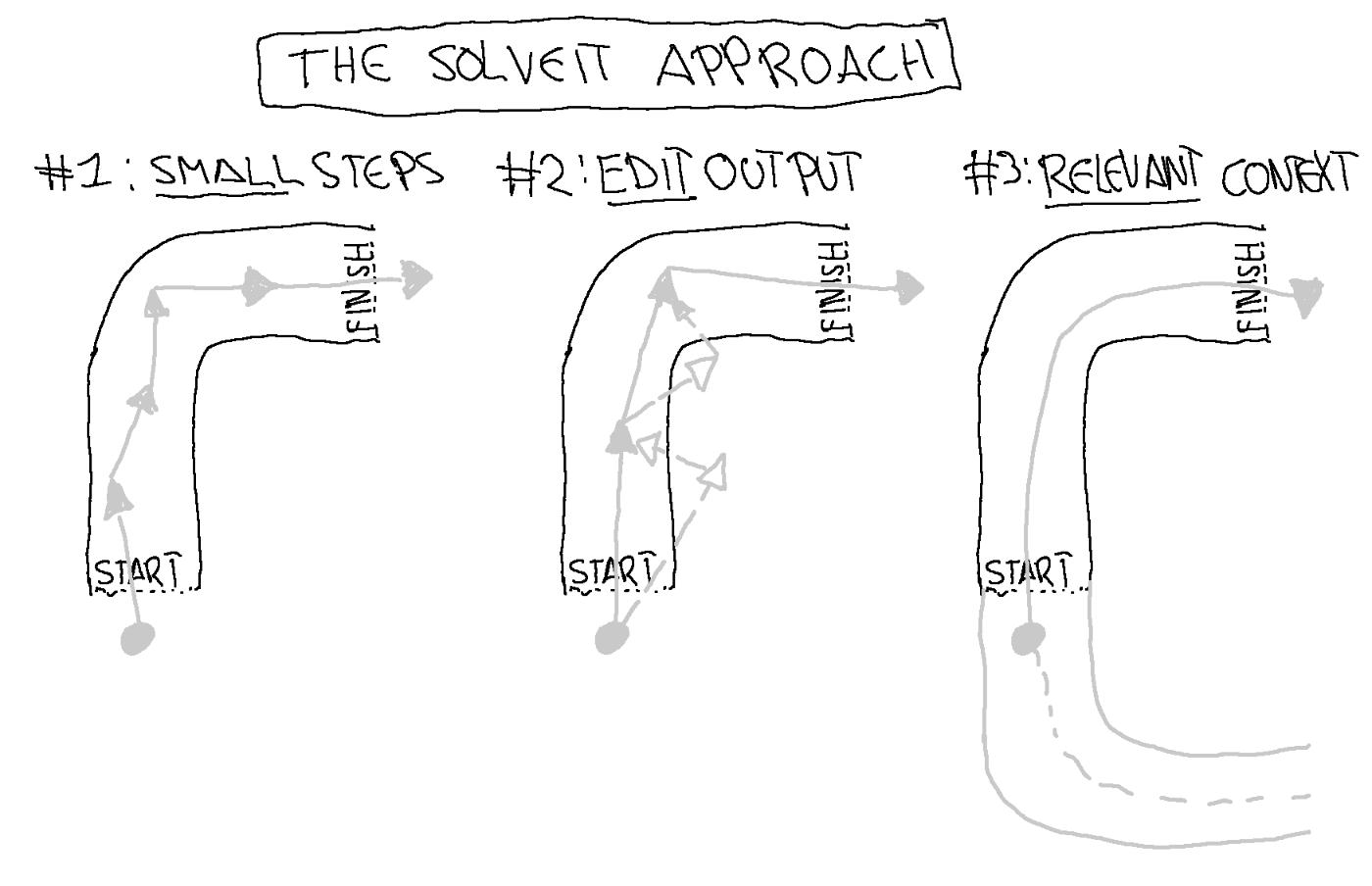
And while the course also introduced the "Solveit" tool, which is specifically designed to work with this approach, the principles apply to any AI interaction. Whether you're using ChatGPT, Claude Code, Github Copilot, Cursor, or any other AI tool.
So even if you don't have access to Solveit, I'm sure you'll find something valuable in this post.
Disclosure: After the course I ended up working at AnswerAI...that's how much I love the approach!
TIL: Fix Key Repeat in VSCode/Cursor on macOS for Vim bindings
By default, macOS shows accent options (é,è,ê) when holding keys - great for typing. But it’s problematic in apps like VSCode and Cursor where you may have enabled Vim bindings. Then you want key repeat, like holding ‘j’ to move down in Vim.
Here’s how to enable key repeat instead:
VSCode:
defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool false
Cursor:
defaults write com.todesktop.230313mzl4w4u92 ApplePressAndHoldEnabled -bool false
To revert back to accent menu:
defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool true
defaults write com.todesktop.230313mzl4w4u92 ApplePressAndHoldEnabled -bool true
Remember to restart the app after applying.
Note: Cursor’s unusual bundle ID is permanent due to app release constraints (source). You can identify bundle id’s yourself by running osascript -e 'id of app "Cursor"'
DIY LLM Evaluation: A Case Study of Rhyming in ABBA Schema
Originally posted on Xebia's blog, my employer at the time of writing.
It's becoming common knowledge: You should not choose your LLMs based on static benchmarks.
As Andrej Karpathy, former CTO of OpenAI, once said on Twitter: "I pretty much only trust two LLM evals right now: Chatbot Arena and the r/LocalLlama comments section". Chatbot Arena is a website where you can submit a prompt, see two results, and then choose the best result. All results are then aggregated and scored. On the r/LocalLlama subreddit people discuss finetuning LLMs on custom usecases.
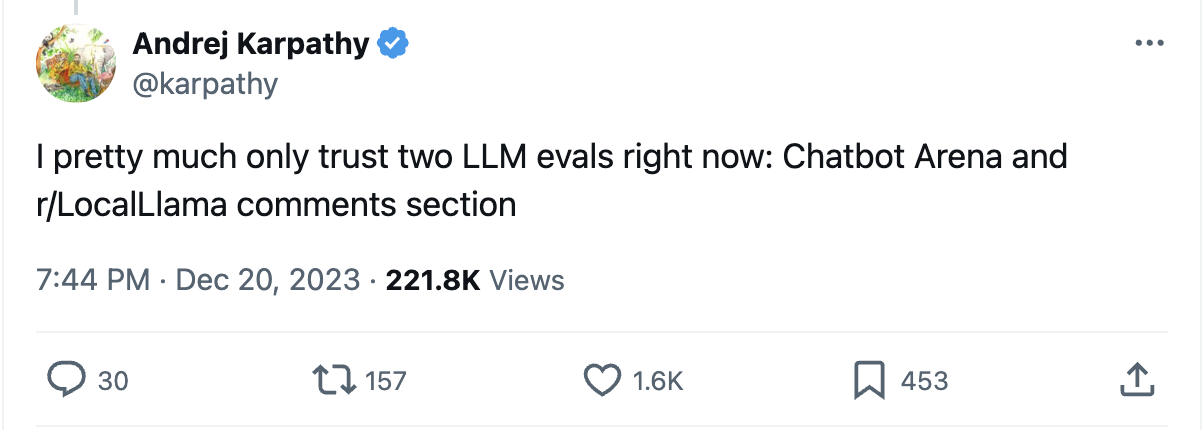
The lesson is: only trust people evaluating LLMs on the tasks they themselves care about.
But there's something better: evaluate LLMs yourself on tasks you care about! Then you do not only get the most relevant scoring metrics for your task. But, in the process, you will also learn a whole lot more about the problem you're actually trying to solve.
In this blogpost, I will share with you my journey into evaluating LLMs on a ridiculous task. I've been obsessed with it for almost a year: rhyming in ABBA schema. For some reason, most LLMs can't create a 4-line poem, where the first line rhymes with the last, and the second rhymes with the third.
Curious to know why this is the case? In this rest of this blogpost I will share with you:
- Why rhyming in ABBA schema is an interesting task
- What the results were of my analysis
- What lessons I learned from going through this exercise
📊 How to explain your analytics use case in 4 steps without losing your audience
Originally posted on Xebia's blog.

We see many data scientists struggle in explaining the use case they're working on.
And that's such a shame!
In this short post we explain the 4-step framework to connect with your audience.
🤦♂️ I accidentally deleted my shell config: Three tips for preventing it happening again
Originally posted on twitter.
Yesterday I messed up 🤦♂️ I accidentally deleted my shell config file.
It was a brain fart. I wanted to open the file with vim. Instead I typed rm.
rm ~/.zshrc
It happened in the office. I felt so stupid. My colleagues made a fun of me. But they also showed me a cool tool to avoid making this mistake again.
So here's how to protect yourself against accidentally deleting config files:
📊 Datasets poem
Originally posted on twitter.
Titanic is tiring 🚢
Iris is irritating 🥀
MNIST is too easy 🥱
Boston makes me queasy 🤢
California housing is not so bad 🏡
Sentiment analysis just makes me sad 🥲
Here are the datasets that I gravitate to... 🧵
What about you? 🙌
🎤 How to spend less time preparing presentations with a universal outline
Originally posted on twitter.
I used to spend a lot of time outlining my presentations.
But for the past two years or so I've been using this framework and it helped me focus on the content instead. It basically turns outlining into a color by numbers challenge. I learned it from a Dutch book called Story Design by Farah Nobbe and Natalie Holwerda-Mieras.
The book is only available in Dutch so I thought I'd outline the framework here.
🔄 How to iterate on data to improve your models
Originally posted on twitter.
How do you iterate on the data to improve your models?
At NeurIPS I saw a talk by Peter Mattson and Praveen Paritosh about DataPerf.

They share a framework of three types of tasks and how to benchmark them:
- Training data
- Test data
- Algorithms to automate data work
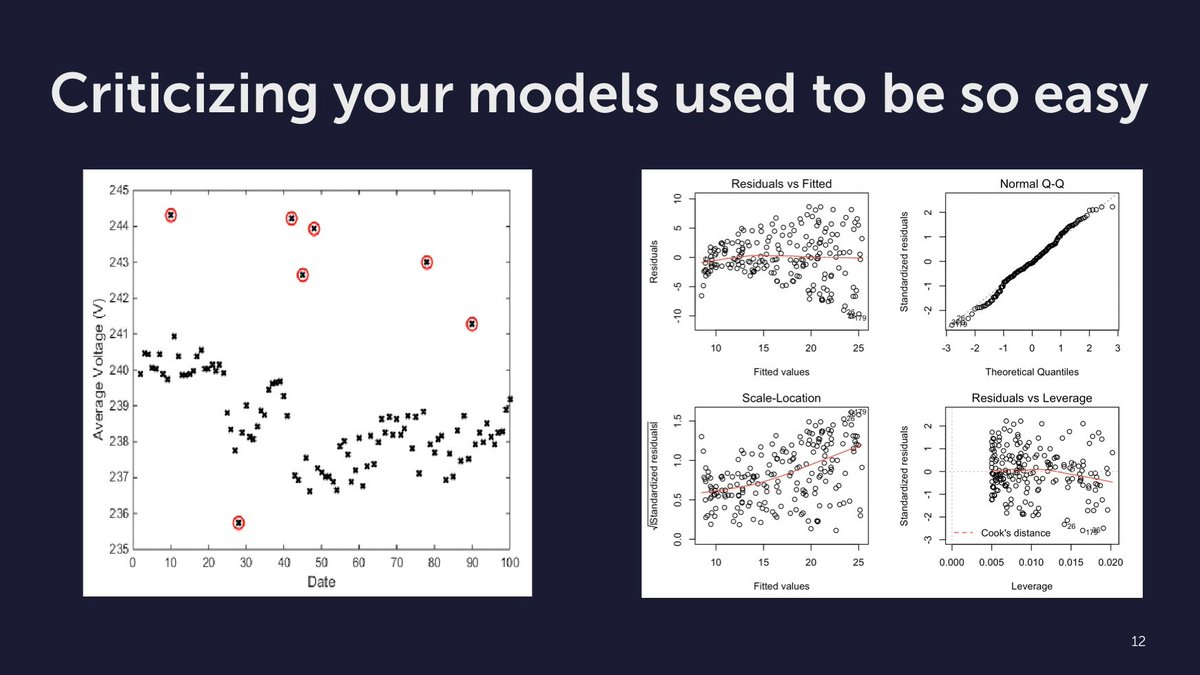
Criticizing Models
Originally posted on twitter.
Criticizing your models is an important part of modeling.
In statistics this is well recognized. We check things like heteroskedasticity to avoid drawing the wrong conclusions.
What do you do in machine learning? Only check cross-validation score?
📊 Using imgcat to display matplotlib plots in iTerm
Originally posted on twitter.
Does anyone else use the imgcat library to show matplotlib plots directly in iTerm?
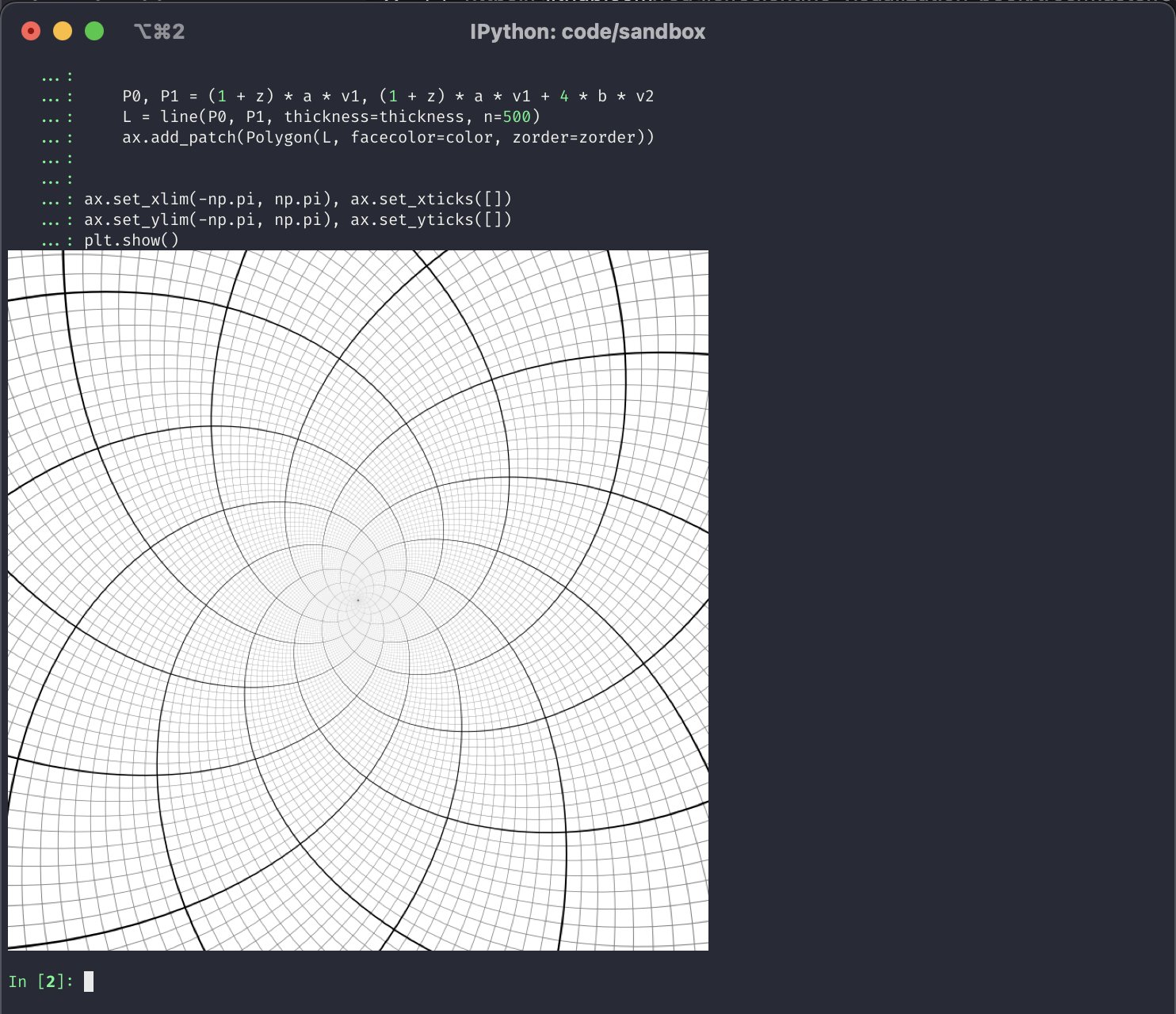
Image credits: Nicolas P. Rougier's Scientific Visualization book
Yes, plotting in Jupyter is nicer...but I think it's pretty neat that this is possible. And sometimes it's quicker too 😁
📊 Three types of metrics for data science projects in professional organizations
If you're working on a data science project in a professional organization you'll need to show the value you contribute. That's where metrics come in.
But choosing a metric is hard. Because there's usually multiple factors at play. I've encountered that in my daily work as a data scientist.

I've found it useful to organize metrics in three level framework. I learned about it in the book "Trustworthy Online Controlled Experiments" (Kohavi, Tang, and Xu, 2020).
I'll explain the three types of metrics below.
🎯 Three questions I ask myself when setting personal development goals
A colleague asked me how I set my goals. I never thought about it explicitly but wrote it down for them and figured I could share it here too. This is just something that works for me. So take it with a grain of salt🧂
I write down a goal and ask myself three questions:
- 💗 Do I get excited about my goal?
- 💡 Will I learn valuable things while trying to achieve the goal?
- 🙌 If I achieve the goal, can I share my success with others?
Brain Storming is the worst. Brain Writing is a bit better
Facilitating a brain storm is easy right?
Tell people to write ideas on stickies. Group them. Discuss. Dot-vote. Done.
Wrong! What I've seen too often is: Write. Group. Discuss one idea. Run out of time. Forget about follow-up.
You know you've failed at brain storming when... You need to make a decision right now, because the meeting is out of time.
Here's three reasons brain storming fails:
- 🙊 Discussing ideas one by one means only one idea is improved at a time
- 📣 The loudest voice in the room dominates the discussion
- 📒 Cryptic messages on stickies mean ideas aren't captured
Here's a different technique called "brain writing" that I enjoy:
Why you should care about Data-Centric AI
If you care about delivering value with data science you should probably care about Data-Centric AI.
Data-Centric AI is about iterating on the data instead of the model architecture to create good machine learning models.
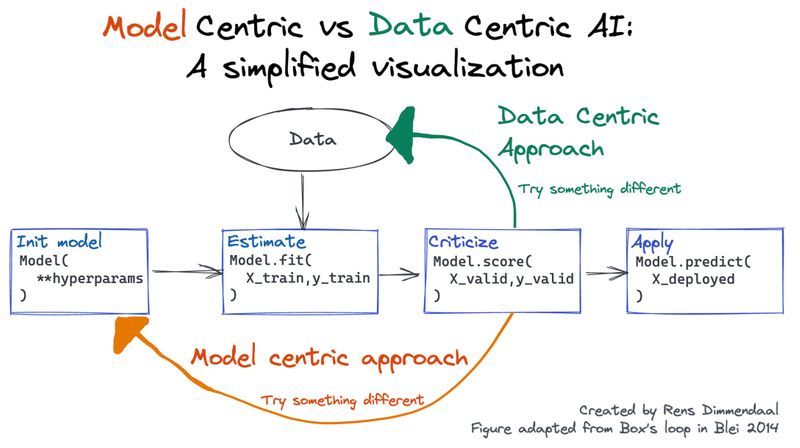
Read the full thread on Twitter where I explain why this approach matters for practical applications.
Better keyboard shortcuts with the Hyper Key
Originally posted on twitter.
What's the first thing you do when you get a new mac? 🧑💻
For me it's setup the hyper key.
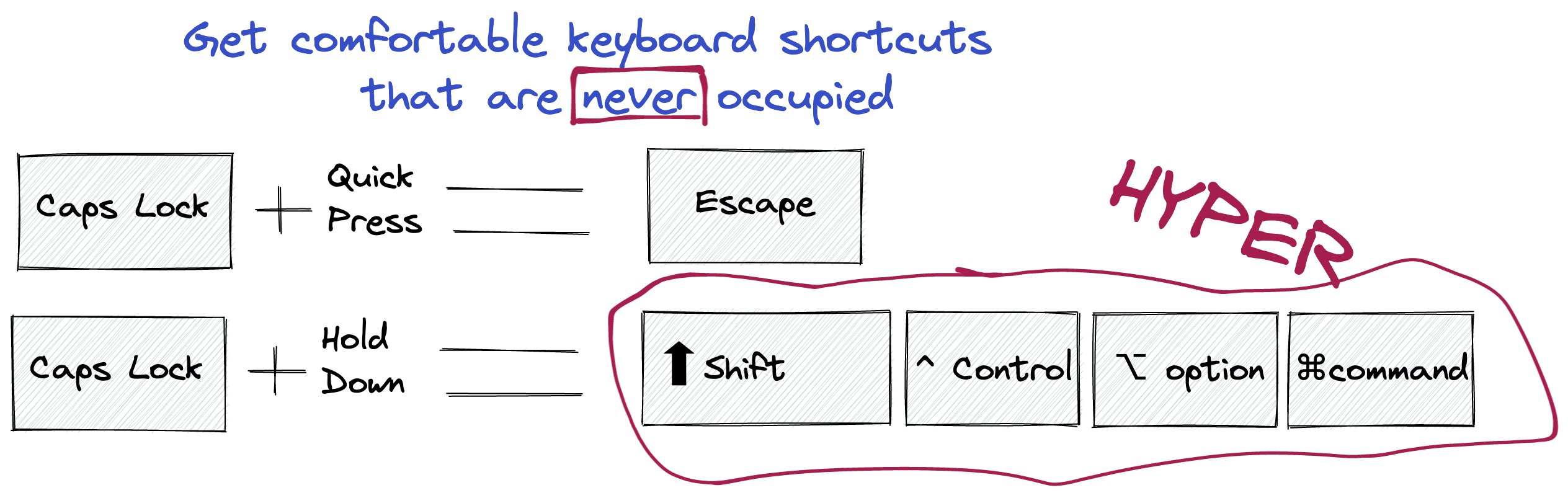
It removes your caps lock functionality and gives you something much much better:
1️⃣ an escape key that's comfy for your pinky 2️⃣ a hyper key that's never occupied by other shortcuts
No other app uses these shortcuts:
⬆️ shift ^ control ⌥ option ⌘ command +...another letter
So if you get the hyper key you get a comfortable shortcut combination that's never blocked!
And that's important, when you want to have some shortcuts available everywhere.
Keep reading for examples:
🪤 One trap that keeps techies from connecting with their audience
Have you ever felt excited to share something? A blogpost, a sales pitch, or presentation? And have you felt sad or frustrated when you didn't get the positive response you were looking for?
Did you think to yourself: but I really have a great solution!?
Then I know your pain. And there is one trap I keep falling into and see others fall in all the time as well. I see it most often when techies try to pitch a technical solution. Here's the mistake:
Your audience's problem is NOT the absence of your solution
✍️ How to make your docs a pleasure to read AND write
Have you ever had to work your way through bad software documentation? Couldn't find what you needed?
Or have you postponed writing the documentation for a project because you didn't know where to start?
Well if you ever have the chance to setup documentation for a project then you should consider organizing it according to the "Divio Documentation Framework".

Winner of the Data-Centric AI Competition

Proud to announce that my team was one of the winners in Andrew Ng's Data-Centric AI Competition! This competition focused on improving model performance by enhancing the dataset rather than changing the model itself.
To learn more about our approach and the data-centric techniques we used, check out our detailed blog post where we share the three key tips that helped us succeed.
We also shared a blogpost on DeepLearning.AI about our experience with the competition.
Three tips for Data-Centric AI and one data science lesson
This blog was originally posted at Xebia.com, my employer at the time of writing.
Andrew Ng (co-founder of Coursera, Google Brain, deeplearning.ai, landing.ai) is most famous for his Machine Learning course on Coursera. It teaches the basics of machine learning, how to create models and how to use them to predict with great accuracy.
Recently, he has introduced the concept of Data-Centric AI. The idea is that rather than treating your dataset as fixed and solely focus on improving your model setup, it focuses on improving your dataset. He argues that this is often much more effective to improve your performance.
Catching chatbots by the long tail
This blog was originally posted at Xebia.com, my employer at the time of writing.
Have you ever had a conversation with a chatbot? Was it a positive experience? It might have been. But more likely than not it left you a bit frustrated. Chatbots try to understand your message and help you with an appropriate response. However, most of the time they're not that great yet. In a way chatbots are like baseball players.
"Baseball is the only field of endeavor where a man can succeed three times out of ten and be considered a good performer." — Ted Williams, baseball Hall of Famer
The same holds true for chatbots. A deflection percentage of 32% [users helped by the bot without human intervention] is what google considers a success story!
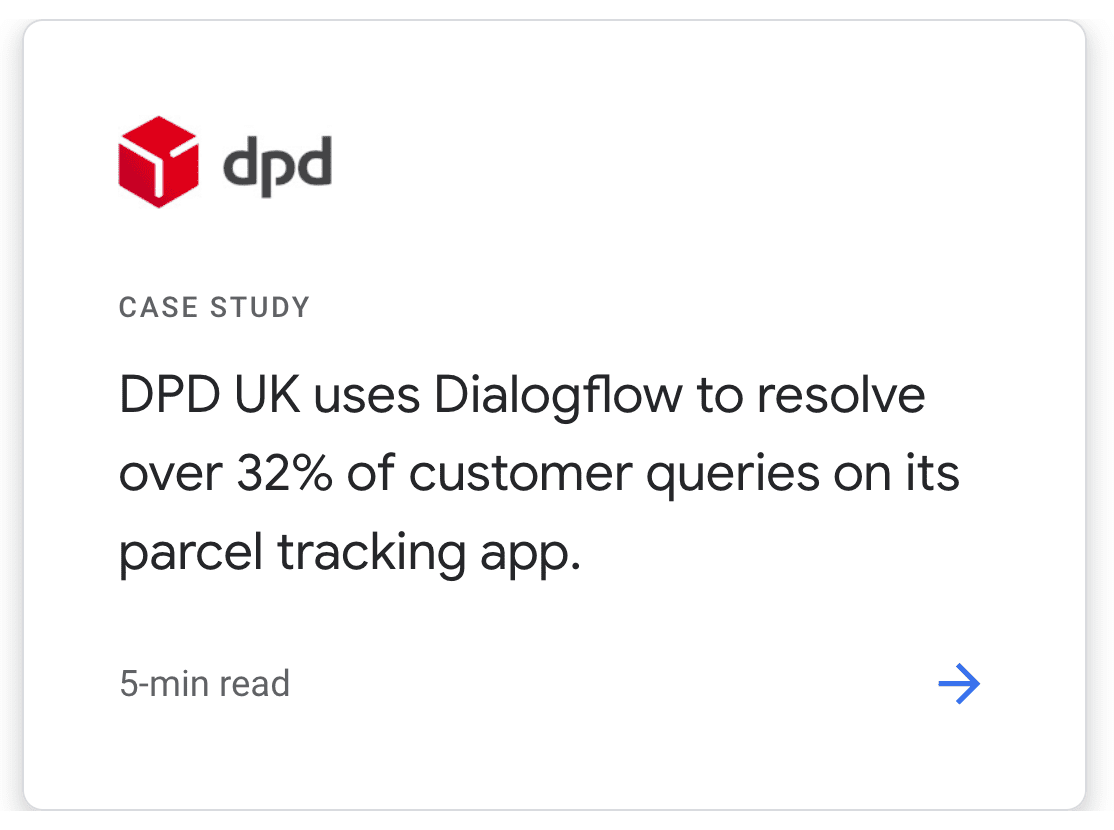 Customer Story on Google Dialogflow's website. Retrieved 20 April 2021
Customer Story on Google Dialogflow's website. Retrieved 20 April 2021
As a data science consultant I've worked with multiple companies on chatbots and helped them do better. During these projects I have discovered a pattern that might help others build better chatbots too. In this article I outline three tips that should help you focus on what matters.
Rhyme with AI
This blog was originally posted at Xebia.com, my employer at the time of writing.
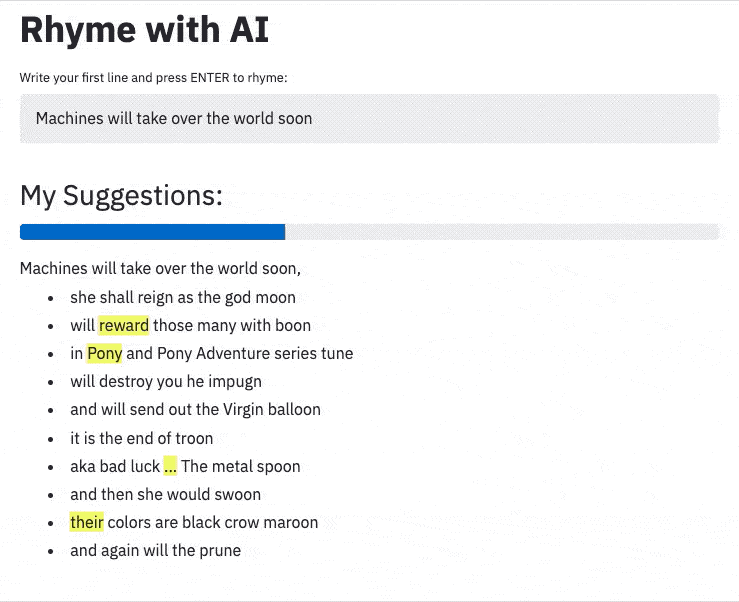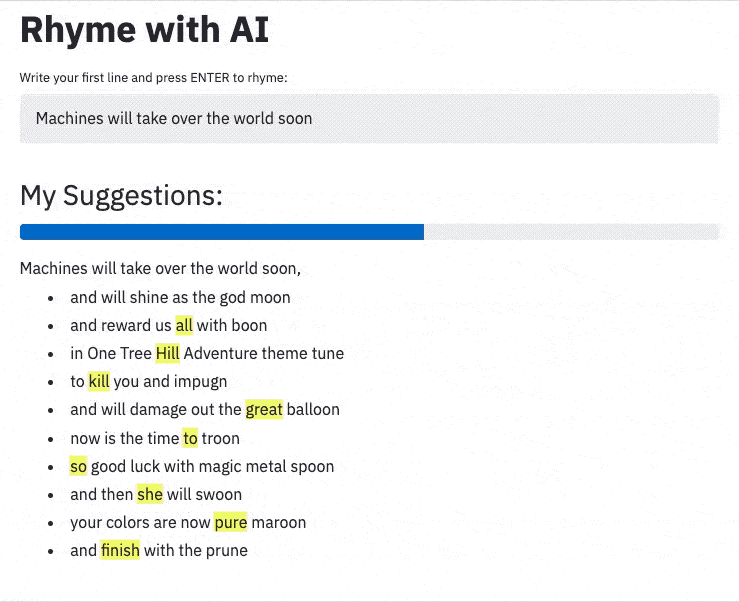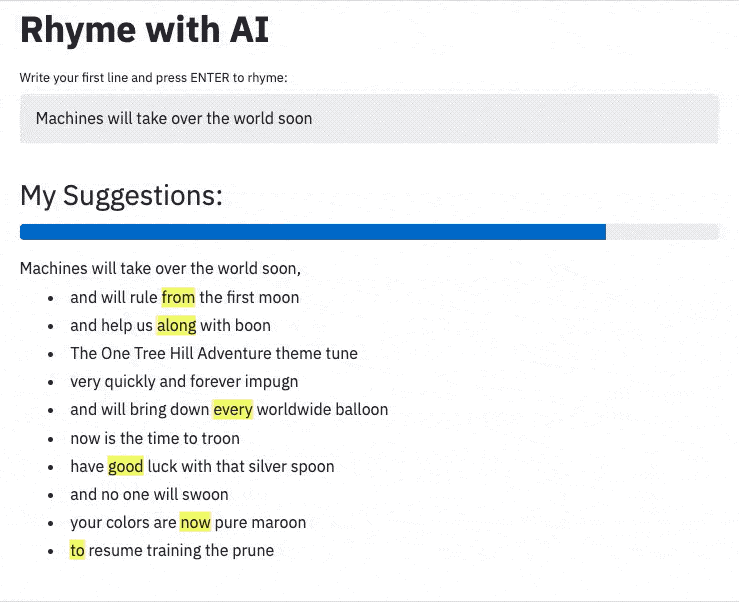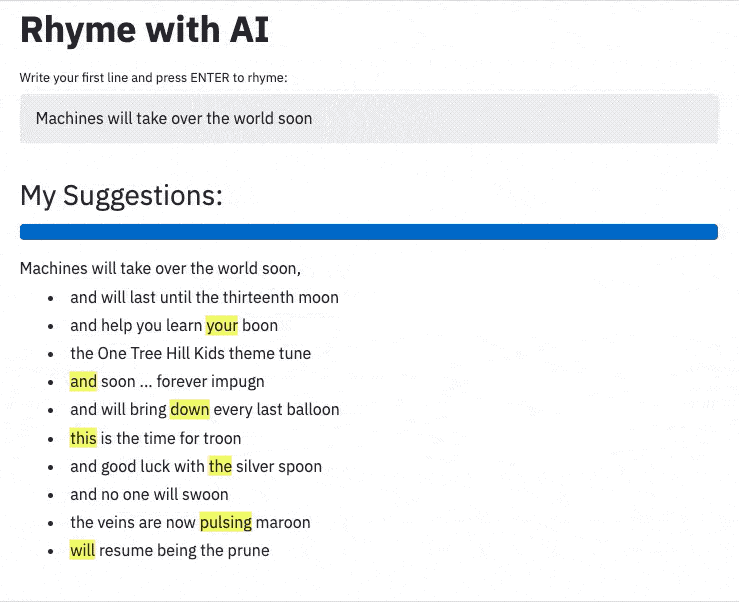
Machines may take over the world within the year;
But creating rhymes instills in us the most fear!
Luckily, pre-trained neural networks are easy to apply.
With great pride we introduce our new assistant: Rhyme with AI.